Trekkerdata
Machine- en trekkerdata zelf beheren
Fabrikanten van trekkers en machines investeren flink in hun eigen technologie, en ook steeds meer in het uitwisselbaar maken van data tussen verschillende systemen. Als boer verkrijg je toegang tot deze data via de cloudomgeving van je fabrikant. De fabrikant stelt slechts een deel van deze data beschikbaar. In het uitwisselbaar maken van data stellen ze prioriteiten en zoeken ze naar commerciële kansen. Belangrijke parameters zoals de hefbelasting, motorbelasting en het brandstofverbruik, maar ook werktuigdata zoals opbrengstdata en “as-applied” data zijn hier voorbeelden van. Dit levert een ongelijkwaardige positie op. Waar voor de fabrikant alle data uit de trekker-werktuig combinatie beschikbaar is, wordt andersom verzoeken om data aan fabrikanten vaak nog geweigerd onder het mom van ‘het geheim van de chef’.
Als je autonoom over je machinedata wil kunnen beschikken, ongeacht het merk of type machine, dan kun je ervoor kiezen om eigen apparatuur op de trekker te plaatsen. Daarmee wordt het mogelijk om zonder tussenkomst van de fabrikant over alle (ruwe) data te beschikken. Een bijkomend voordeel is dat je op deze manier direct vanaf de trekker alle data op 1 plek bij elkaar kunt brengen, zodat je minder last hebt van de wildgroei aan platforms en cloudoplossingen. Iets waar je met een kleurrijk machinepark al snel mee te maken hebt.
Zelf trekkerdata loggen: doen of niet?
Is het zinvol om als teler en veehouder te investeren in het zelf loggen, structureren en opslaan van je data of kun je dat beter aan de trekkerfabrikanten en machinebouwers overlaten? Met deze vraag is in 2019 een project opgestart om zelf trekker- en machinedata te ontsluiten. Duidelijk werd dat het zelf aan de slag gaan met trekker- en machinedata een heel karwei is. Want met directe toegang en ruwe data alleen ben je er nog niet. Er is software nodig om bepaalde data uit de trekker op te vragen en de data te vertalen naar begrijpelijke waardes (decodering). Belangrijke uitdagingen bleken een goede structurering van de data, compatibiliteit en het op een efficiënte wijze verwerken van de grote hoeveelheden data.
Vasthouden aan je eigen trekkerdata strategie wordt ook moeilijker als je ziet hoe snel fabrikanten zelf gaan. Het wordt dan wel erg verleidelijk om daar gewoon in mee te gaan.
Toch is het al een belangrijke en betekenisvolle stap om toegang tot je eigen ruwe data te hebben.
Bodemgegevens worden bijvoorbeeld alleen maar belangrijker. Door nu eerst alle data over de bodem goed te verzamelen, inclusief wat je trekker en werktuig daarover zeggen, stelt je in staat om daar met kennis van buiten of later met nieuwe kennis, slimme dingen mee te doen. Los van je fabrikant, met een eigen lokale IT partij of binnen een studieverband, kun je dan werken aan eigen formules en analyses. Het geeft je een stuk autonomie als boer.
Bij het ontwikkelen van IT wordt het snel complex. Het is heel belangrijk dat je vanaf het begin de toepassing duidelijk in beeld hebt, zodat je weet welke functionaliteit de toepassing echt moet bevatten om de gebruiker te interesseren. Daarom is het uitwisselen van ideeën tussen boeren en technologie aanbieders meteen vanaf de start heel waardevol.
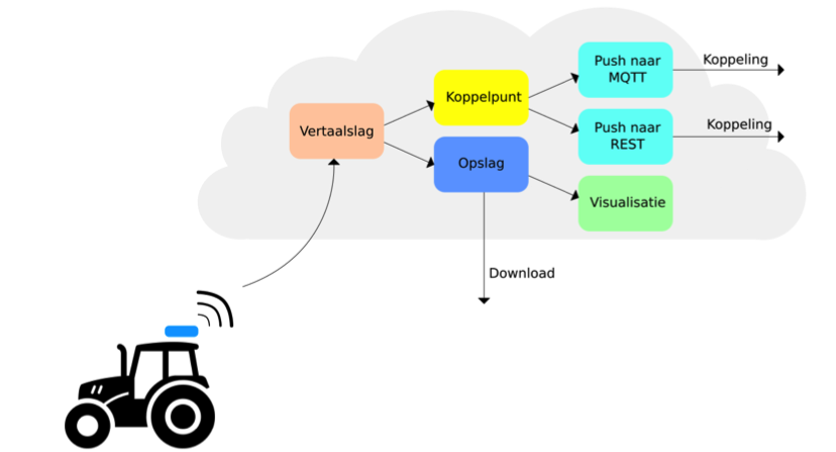
Het lijkt een relatief simpel figuur. Maar zodra je meer verdieping zoekt wordt het heel snel heel veel en heel complex. Te complex voor een individuele boer. Het is belangrijk dat de data continu doorstroomt en dat we zo dicht mogelijk bij de ruwe data komen.
Bodem
Een voorbeeld hiervan is het inzichtelijk maken van bodemverdichting aan de hand van de gemeten snelheid, brandstofverbruik en motorkoppel van de trekker.
Wanneer een geproduceerde datakaart echt bruikbaar is in de praktijk is lastig te bepalen. Wanneer geeft zo’n kaart genoeg informatie om bijvoorbeeld een uitgebreider onderzoek te starten of om anders te handelen op de verdichte stukken? Vaak is het maar een deel van de puzzel en kan alleen door slim combineren van verschillende databronnen de juiste conclusie en oplossing gevonden worden. Zie hier weer de centrale positie van de boer in het gehele speelveld. Op de boerderij komen de verschillende databronnen samen.
Conclusies
De technologieleverancier staat voor tal van keuzes, bijvoorbeeld rond de meettechniek, het bouwen van datakoppelingen en de weergave van de data. Hoe meer data, des te waardevoller de toepassing wordt. Maar dat maakt het ook complex en duur. Een boer kan het beste beoordelen welke datalagen echt meerwaarde leveren. Op die manier zit er dus echt meerwaarde in de interactie tussen boeren en technologie leveranciers.
In technisch opzicht is de heilige graal voor trekker- en machinedata om relevante data op plaats en tijd opvraagbaar te maken en ook algoritmes op die wijze met onderliggende data te voeden.
Een interessante route is om de huidige software voor isobus verzameling en de decodering open source beschikbaar te stellen. Zodoende kan er infrastructuur ontwikkeld worden die recht doet aan de positie van de boer, met een veilige plek om data te bewaren en de boer kan beslissen wat er met de data gebeurt.
Een tweede route kan zijn om als boeren te verenigen in een coöperatie. De coöperatie kan dan zorgen voor een versnelling, door de vertaling voor specifieke onderdelen op te pakken, prioriteiten te stellen en de kosten en baten van decodeerwerk over alle leden te verdelen. Als zo’n coöperatie dan ook nog een strategie ontwikkelt om de gegevens te combineren met meta data, en die inzichten beschikbaar te maken voor de leden (en eventueel te verwaarden naar derden), dan heb je een interessant model te pakken. Maar om dat speelveld te overzien, en de capaciteit te organiseren om alle benodigde stappen te nemen, daar liggen nog wel aantal grote hobbels op de weg.